Okhttp

exectute执行
真正的请求交给了 RealCall 类, exectute()方法执行RealCall的execute方法
client.dispatcher().enqueue(new AsyncCall(responseCallback));
Dispatcher调用enqueueAsyncCall将 call 加入到队列中,然后通过线程池来执行call
Dispatcher是一个任务调度器,它内部维护了三个双端队列:
readyAsyncCalls:准备运行的异步请求
runningAsyncCalls:正在运行的异步请求
runningSyncCalls:正在运行的同步请求
线程池: new CachedThreadPool(), 默认最大64线程并发,同域名下5个。finish()之后转移call列表。
public synchronized ExecutorService executorService() {
if (executorService == null) {
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS, new SynchronousQueue<>(), Util.threadFactory("OkHttp Dispatcher", false));
}
return executorService;
}阻塞队列用的SynchronousQueue,它的特点是不存储数据,当添加一个元素时,必须等待一个消费线程取出它,否则一直阻塞。
采用责任链的模式来使每个功能分开,每个Interceptor自行完成自己的任务, 将处理者和请求者进行解耦
多个对象都有机会处理请求,将这些对象连成一个链,将请求沿着这条链传递。如:View的事件机制
拦截器
拦截器把实际的网络请求、缓存、透明压缩等功能都统一了起来,每一个功能都只是一个 Interceptor,它们再连接成一个 Interceptor.Chain,环环相扣,最终圆满完成一次网络请求。
retryAndFollowUpInterceptor : 失败和重定向拦截器, 当请求内部抛出异常时,判定是否需要重试
BridgeInterceptor: 封装request和response拦截负责把用户构造的请求转换为发送到服务器的请求把服务器返回的响应转换为用户友好的响应
CacheInterceptor: 当在OkHttpClient中配置了缓存,则将这个Resposne缓存起来,使用DiskLruCache
ConnectInterceptor: 连接服务,负责和服务器建立连接, 负责了Dns解析和Socket连接
CallServerInterceptor: 传输http的头部和body数据
addInterceptor 和 addNetworkdInterceptor区别
Interceptors 和 networkInterceptors 一个在 RetryAndFollowUpInterceptor 的前面,一个在后面
责任链调用图可以分析出来,假如一个请求在 RetryAndFollowUpInterceptor 这个拦截器内部重试或者重定向了 N次,那么其内部嵌套的所有拦截器也会被调用N次,同样 networkInterceptors 自定义的拦截器也会被调用 N次。而相对的 Interceptors 则一个请求只会调用一次,所以在OkHttp的内部也将其称之为 Application Interceptor。
Okhttp连接池
连接池是为了解决频繁的进行建立Sokcet连接(TCP三次握手)和断开Socket(TCP四次分手),采用Socket复用
get:http 1.x协议下,所有的请求的都是顺序的,正在写入数据的socket无法被另一个请求复用。http2.0协议使用了多路复用技术,允许同一个socket在同一个时候写入多个流数据。http1.x协议下当前socket没有其他流正在读写时可以复用,否则不行,http2.0对流数量没有限制。
put:在连接池中找连接的时候会对比连接池中相同host的连接。如果在连接池中找不到连接的话,会创建连接,创建完后会存储到连接池中。
LruCache的原理
LruCache的实现 LinkedHashMap,需要两个数据结构:双向链表和哈希表。
双向链表用于记录元素被塞进cache的顺序,然后淘汰最久未使用的元素。
哈希表用于直接记录元素的位置,即用O(1)的时间复杂度拿到链表的元素。
get的操作逻辑:根据传入的key(图片url的MD5值)去哈希表里拿到对应的元素,如果元素存在,就把元素挪到链表的尾部。
put的操作逻辑:首先判断key是否在哈希表里面,如果在的话就去更新值,并把元素挪到链表的尾部。如果不在哈希表里,说明是一个新的元素。这时候需要去判断此时cache的容量了,如果超过了最大的容量,就淘汰链表头部的元素,再将新的元素插入链表的尾部,如果没有超过最大容量,直接在链表尾部追加新的元素。
RxJava
RxJava是一种基于观察者模式的响应式编程框架
Observable.create(new ObservableOnSubscribe()) //创建一个事件流,参数是我们创建的一个事件源
.map(...) //有时我们会需要使用操作符进行变换
.subscribeOn(Schedulers.io()) //指定事件源代码执行的线程
.observeOn(AndroidSchedulers.mainThread()) //指定订阅者代码执行的线程
.subscribe(new Observer()) //参数是我们创建的一个订阅者,在这里与事件流建立订阅关系Observable:俗称被订阅者,被订阅者是事件的来源,接收订阅者(Observer)的订阅,然后通过发射器(Emitter)发射数据给订阅者。
Observer:俗称订阅者,注册过程传给被订阅者,订阅者监听开始订阅,监听订阅过程中会把Disposable传给订阅者,然后在被订阅者中的发射器(Emitter)发射数据给订阅者(Observer)。
Emitter:俗称发射器,在发射器中会接收下游的订阅者(Observer),然后在发射器相应的方法把数据传给订阅者(Observer)。
Consumer:俗称消费器,消费器其实是Observer的一种变体,Observer的每一个方法都会对应一个Consumer,比如Observer的onNext、onError、onComplete、onSubscribe都会对应一个Consumer。
Disposable:是释放器,通常有两种方式会返回Disposable,一个是在Observer的onSubscribe方法回调回来,第二个是在subscribe订阅方法传consumer的时候会返回。
数据源生产事件的subscribe方法只有在observable.subscribe(observer)被执行后才执行的。 换言之,事件流是在订阅后才产生的。而observable被创建出来时并不生产事件,同时也不发射事件。
四种事件流:onSubscribe(订阅事件),onNext(正常事件),onError(异常事件),onComplete(完成事件)
订阅是从下游的Observer向上游的Observable发送订阅,然后在订阅的过程中,给下游的Observer发送订阅监听,并且给上游的被观察者添加订阅。
流程
- Observable.create 创建事件源,但并不生产也不发射事件。
- 实现 observer接口,但此时没有也无法接受到任何发射来的事件。
- 订阅 observable.subscribe( 此时会调用具体 Observable的实现类中的subscribeActual方法,此时会才会真正触发事件源生产事件,事件源生产出来的事件通过 Emitter的 onNext onError onComplete发射给observer对应的方法由下游 observer消费掉。从而完成整个事件流的处理。
observer中的onSubscribe在订阅时即被调用,并传回了Disposable, observer中可以利用Disposable来随时中断事件流的发射。
实现线程切换
RxJava的调度线程是通过subscribeOn方法将上游生产事件的方法运行在指定的调度线程中。
subscribeOn 是通过新建 Observable 的方式,使用 OnSubscribe 类的方式去做到线程切换的。
observeOn 是通过 operator 操作符的形式去完成线程切换的,所以他的作用域和其他操作符一样,是调用 observeOn 之后的链路。
Schedulers.io() 代表 io 操作的线程, 通常用于网络,读写文件等 io 密集型的操作
Schedulers.computation() 代表 CPU 计算密集型的操作, 例如需要大量计算的操作
Schedulers.newThread() 代表一个常规的新线程
AndroidSchedulers.mainThread() 代表 Android 的主线程
RxJava的subscribeOn只有第一次生效?
subscribeOn是规定上游的observable在哪个线程中执行,如果我们执行多次的subscribeOn的话,从下游的observer到上游的observable的订阅过程, 最开始调用的subscribeOn返回的observable会把后面执行的subscribeOn返回的observable给覆盖了,因此我们感官的是只有第一次的subscribeOn能生效。
那如何才能知道它实际在里面生效了呢,我们可以通过doOnSubscribe来监听切实发生线程切换了。
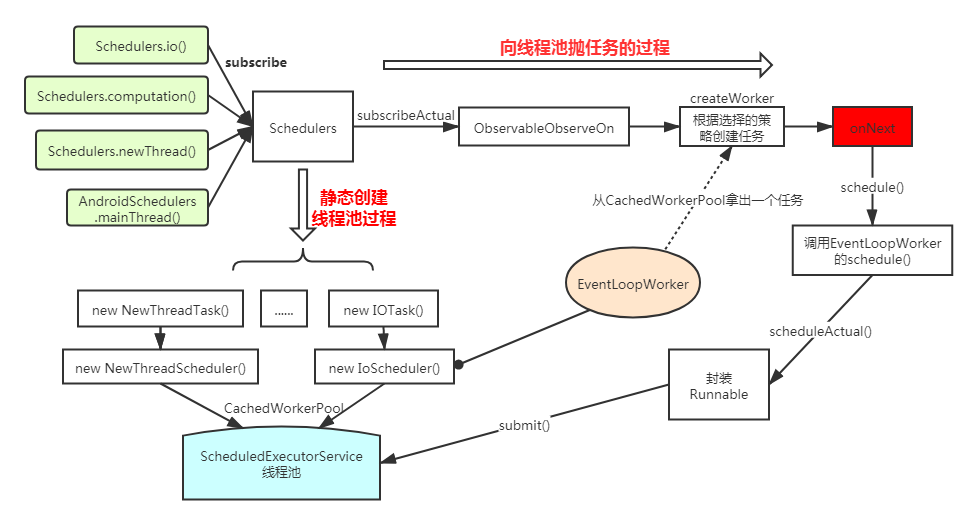
生产者线程调度流程概括
Schedulers.io()等价于 new IoScheduler()。
new IoScheduler() Rxjava 创建了线程池,为后续创建线程做准备,同时创建并运行了一个清理线程 RxCachedWorkerPoolEvictor,定期执行清理任务。
subscribeOn()返回一个 ObservableSubscribeOn 对象,它是 Observable 的一个装饰类,增加了 scheduler。
调用 subscribe()方法,在这个方法调用后,subscribeActual() 被调用,才真正执行了
IoSchduler 中的 createWorker() 创建线程并运行,最终将上游 Observable 的 subscribe() 方法调度到新创建的线程中运行。
消费者线程调度流程概括
Rxjava调度消费者现在的流程,以observeOn(AndroidSchedulers.mainThread())为例:
1.AndroidSchedulers.mainThread()先创建一个包含 handler 的 Scheduler, 这个 handler 是主线程的 handler。
2.observeOn 方法创建 ObservableObserveOn,它是上游 Observable 的一个装饰类,其中包含前面创建的 Scheduler 和 bufferSize 等.
3.当订阅方法 subscribe 被调用后,ObservableObserveOn 的 subscribeActual 方法创建 Scheduler.Worker 并调用上游的 subscribe 方法,同时将自身接收的参数observer用装饰类 ObserveOnObserver 装饰后传递给上游。
4.当上游调用被 ObserveOnObserver 的 onNext、onError 和 onComplete 方法时,ObserveOnObserver 将上游发送的事件通通加入到队列 queue 中,然后再调用 scheduler将处理事件的方法调度到对应的线程中(本例会调度到 main thread)。 处理事件的方法将queue 中保存的事件取出来,调用下游原始的 observer 再发射出去。经过以上流程,下游处理事件的消费者线程就运行在了 observeOn 调度后的 thread 中。
总结
Schedulers 内部封装了各种 Scheduler。每一个 Scheduler 中都封装的有线程池,用于执行后台任务。
Scheduler 是所有调度器实现的抽象父类,子类可以通过复写其 scheduleDirect() 来自行决定如何调度被分配到的任务;同时通过复写其 createWorker() 返回的Scheduler.Worker 实例来执行具体的某个任务。此处的任务指的是通过 Runnable 封装的可执行代码块。
子线程切换主线程:给主线程所在的Handler发消息,然后就把逻辑切换过去了。
主线程切换子线程:把任务放到线程池中执行就能把执行逻辑切换到子线程
子线程切换子线程:把任务分别扔进两个线程就行了。
Rxjava 的 subscribe 方法是由下游一步步向上游进行传递的。会调用上游的 subscribe,直到调用到事件源。
Rxjava发射事件是由上而下发射的,上游的 onNext、 onError、 onComplete方法会调
用下游传入的 observer的对应方法。往往下游传递的 observer对象也是经过装饰后的
observer对象。 Rxjava就是利用 ObserveOnObserver将执行线程调度后,再调用下
游对应的 onNext、 onError、 onComplete方法,这样下游消费者就运行再了指定的线
程内。 那么多次调用 observeOn调度不同的线程会怎么样呢? 因为事件是由上而下
发射的,所以每 次用 observeOn切换完线程后,对下游的事件消费都有效,比如下游
的 map操作符。最终的事件消费线程运行在最后一个 observeOn切换后线程中。
操作符
map 转换事件,返回普通事件flatMap 转换事件,返回 ObservableconactMap concatMap 与 FlatMap 的唯一区别就是 concatMap 保证了顺序subscribeOn 规定被观察者所在的线程observeOn 规定下面要执行的消费者所在的线程take 接受一个 long 型参数 count ,代表至多接收 count 个数据debounce 去除发送频率过快的项,常用在重复点击解决上,配合 RxBinging 使用效果很好timer 定时任务,多少时间以后发送事件interval 每隔一定时间执行一些任务skip 跳过前多少个事件distinct 去重
操作符 map 和 flatmap 的区别?
map:【数据类型转换】将被观察者发送的事件转换为另一种类型的事件。
flatMap:【化解循环嵌套和接口嵌套】将被观察者发送的事件序列进行拆分 & 转换 后合并成一个新的事件序列,最后再进行发送。
concatMap:【有序】与 flatMap 的 区别在于,拆分 & 重新合并生成的事件序列 的顺序与被观察者旧序列生产的顺序一致。
解决内存泄漏
- 订阅的时候拿到
Disposable,主动调用dispose - 使用
RxLifeCycle - 使用
AutoDispose
RxJava 中 Observable、Flowable、Single、Maybe、Completable 使用时如何选择?
在 RxJava2 里面,Observable、Flowable、Single、Maybe、Completable 这几个在使用起来区别不大,因为他们都可以用一个或多个函数式接口作为参数进行订阅(subscribe),需要几个传几个就可以了。但是从各个的设计初衷来讲,个人感觉最适用于网络请求这种情况的是 Single 和 Completable。
网络请求是一个 Request 对应一个 Response,不会出现背压情况,所以不考虑 Flowable;
网络请求是一个 Request 对应一个 Response,不是一个连续的事件流,所以在 onNext 被调用之后,onComplete 就会被马上调用,所以只需要 onNext 和 onComplete 其中一个就够了,不考虑 Observable、Maybe ;
对于关心 ResponseBody 的情况,Single 适用;
对于不关心 ResponseBody 的情况,Completable 适用。
为什么 subscribeOn() 只有第一次切换有效
因为 RxJava 最终能影响 ObservableOnSubscribe 这个匿名实现接口的运行环境的只能是最后一次运行的 subscribeOn() ,又因为 RxJava 订阅的时候是从下往上订阅,所以从上往下第一个 subscribeOn() 就是最后运行的,这就造成了写多个 subscribeOn() 并没有什么乱用的现象。
背压的策略Flowable
使用Flowable的时候,可观察对象不再是Observable,而是Flowable;观察者不再是Observer,而是Subscriber。Flowable与Subscriber之间依然通过subscribe()进行关联。
由于基于Flowable发射的数据流,以及对数据加工处理的各操作符都添加了背压支持,附加了额外的逻辑,其运行效率要比Observable低得多。
Flowable的异步缓存池不同于Observable,Observable的异步缓存池没有大小限制,可以无限制向里添加数据,直至OOM,而Flowable的异步缓存池有个固定容量,其大小为128。BackpressureStrategy的作用便是用来设置Flowable通过异步缓存池存储数据的策略。
ERROR: 如果放入Flowable的异步缓存池中的数据超限了,则会抛出MissingBackpressureException异常。
DROP: 如果Flowable的异步缓存池满了,会丢掉将要放入缓存池中的数据
LATEST: 与Drop策略一样,如果缓存池满了,会丢掉将要放入缓存池中的数据,不同的是,不管缓存池的状态如何,LATEST都会将最后一条数据强行放入缓存池中。
BUFFER: Flowable的异步缓存池同Observable的一样,没有固定大小,可以无限制向里添加数据,不会抛出MissingBackpressureException异常,但会导致OOM。
MISSING: 通过Create方法创建的Flowable没有指定背压策略,不会对通过OnNext发射的数据做缓存或丢弃处理,需要下游通过背压操作符(onBackpressureBuffer()/onBackpressureDrop()/onBackpressureLatest())指定背压策略。
RxBinding
EventBus
threadMode 是一个 enum,有多种模式可供选择:
- POSTING,默认值,那个线程发就是那个线程收。
- MAIN,切换至主线程接收事件。
- MAIN_ORDERED,v3.1.1 中新增的属性,也是切换至主线程接收事件,但是和 MAIN 有些许区别,后面详细讲。
- BACKGROUND,确保在子线程中接收事件。细节就是,如果是主线程发送的消息,会切换到子线程接收,而如果事件本身就是由子线程发出,会直接使用发送事件消息的线程处理消息。
- ASYNC,确保在子线程中接收事件,但是和 BACKGROUND 的区别在于,它不会区分发送线程是否是子线程,而是每次都在不同的线程中接收事件
Retrofit
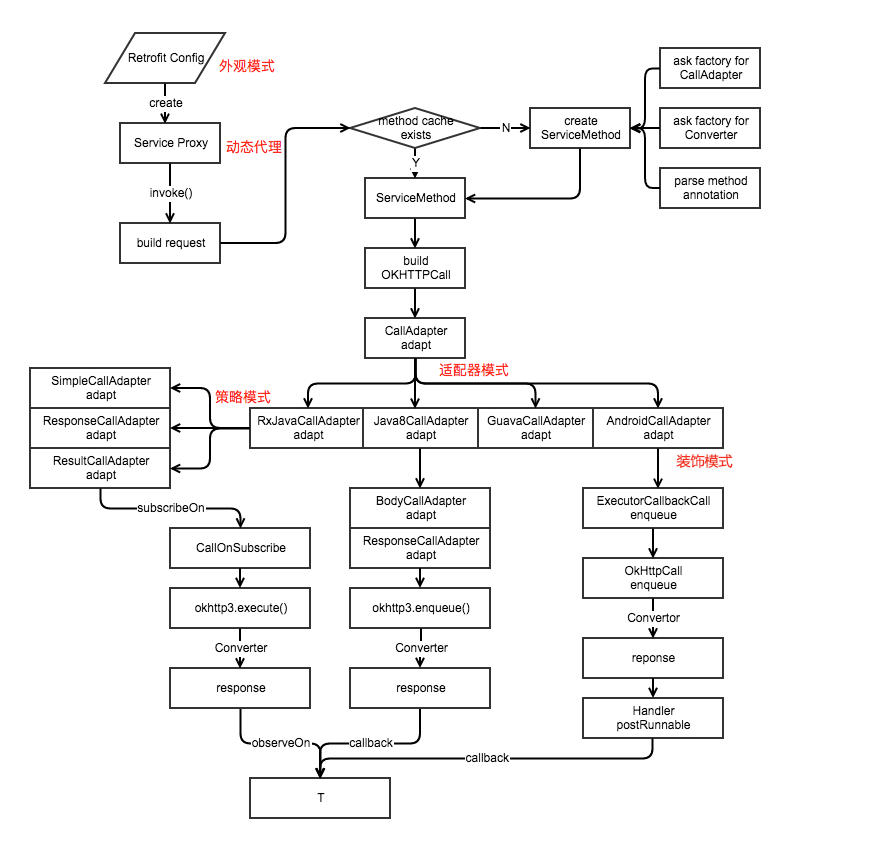
原理
Retrofit 通过 java 接口以及注解来描述网络请求,并用动态代理的方式生成网络请求的 request,然后通过 client 调用相应的网络框架(默认 okhttp)去发起网络请求,并将返回的 response 通过 converterFactorty 转换成相应的数据 model (json,xml),最后通过 calladapter 转换成其他数据方式(如 Rxjava Observable)
涉及到的设计模式
外观模式,构建者模式,工厂模式,代理模式,适配器模式,策略模式,观察者模式
使用Retrofit的七步骤
1.添加Retrofit依赖,网络权限
2.定义接收服务器返回数据的Bean
3.创建网络请求的接口,使用注解(动态代理,核心)
4.builder模式创建Retrofit实例,converter,calladapter…
5.创建接口实例,调用具体的网络请求
6.call同步/异步网络请求
7.处理服务器返回的数据
Retrofit网络通信八步骤
1.创建Retrofit实例
2.定义网络请求接口,并为接口中的方法添加注解
3.通过动态代理生成网络请求对象
4.通过网络请求适配器将网络请求对象进行平台适配
5.通过网络请求执行器,发送网络请求(call)
6.通过数据解析器解析数据
7.通过回调执行器,切换线程
8.用户在主线程处理返回结果
代理
为其他对象提供一种代理,用以控制对这个对象的访问
静态代理:要求被代理类和代理类同时实现相应的一套接口,通过代理类调用重写接口的方法,实际上调用的是原始对象的同样的方法。静态代理类由程序员创建或工具生成代理类的源码,再编译代理类。所谓静态也就是在程序运行前就已经存在代理类的字节码文件,代理类和委托类的关系在运行前就确定了。
动态代理:在程序运行时创建的代理方式;动态代理类是在程序运行期间由 JVM 根据反射等机制动态的生成,所以不存在代理类的字节码文件。代理类和委托类的关系是在程序运行时确定。在接口方法数量比较多的时候,可以进行灵活处理,而不需要像静态代理那样每一个方法进行中转。而且动态代理的应用使类职责更加单一,复用性更强。
Proxy.newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h {
@Override public Object invoke(Object proxy, Method method, @Nullable Object[] args)
})服务接口 使用动态代理
动态代理: 运行时创建的代理类,在委托类的方法前后去做一些事情.在运行过程中,会在虚拟机内部创建一个Proxy的类。通过实现InvocationHandler的接口,来代理委托类的函数。使用动态代理来对接口中的注释进行解析,解析后完成OkHttp的参数构建。
优点: 代理类原始类脱离联系, 在原始类和接口未知的时候 就确定代理类的行为
// 加载ServiceMethod
private final Map<Method, ServiceMethod<?>> serviceMethodCache = new ConcurrentHashMap<>();
ServiceMethod<?> loadServiceMethod(Method method) {
ServiceMethod<?> result = serviceMethodCache.get(method);
if (result != null) return result;
synchronized (serviceMethodCache) {
result = serviceMethodCache.get(method);
if (result == null) {
result = ServiceMethod.parseAnnotations(this, method);
serviceMethodCache.put(method, result);
}
}
return result;
}Retrofit 优点
- 可以配置不同 HTTP client 来实现网络请求,如 okhttp、httpclient 等;
- 请求的方法参数注解都可以定制;
- 支持同步、异步和 RxJava;
- 超级解耦;
- 可以配置不同的反序列化工具来解析数据,如 json、xml 等
- 框架使用了很多设计模式
callAdapterFactory
通过calladapter将原始Call进行封装,找到对应的执行器。如RxjavaCallFactory对应的Observable,转换形式Call
converterFactory
数据解析Converter,将response通过converterFactory转换成对应的数据形式,GsonConverterFactory,FastJsonConverterFactory。
Retrofit
Retrofit核心类,对外提供接口。通过retrofit.create()创建retrofit实例,外观模式。在create()方法中,使用动态代理模式对请求的接口中方法进行封装(ServiceMethod),初始化OkhttpCall。
ServiceMethod
核心处理类,解析方法和注解,toRequest()方法中生成HttpRequest。创建responseConverter(将response流转换为String或实体),创建callAdapter
OkhttpCall
是对okhttp3.Call的封装调用
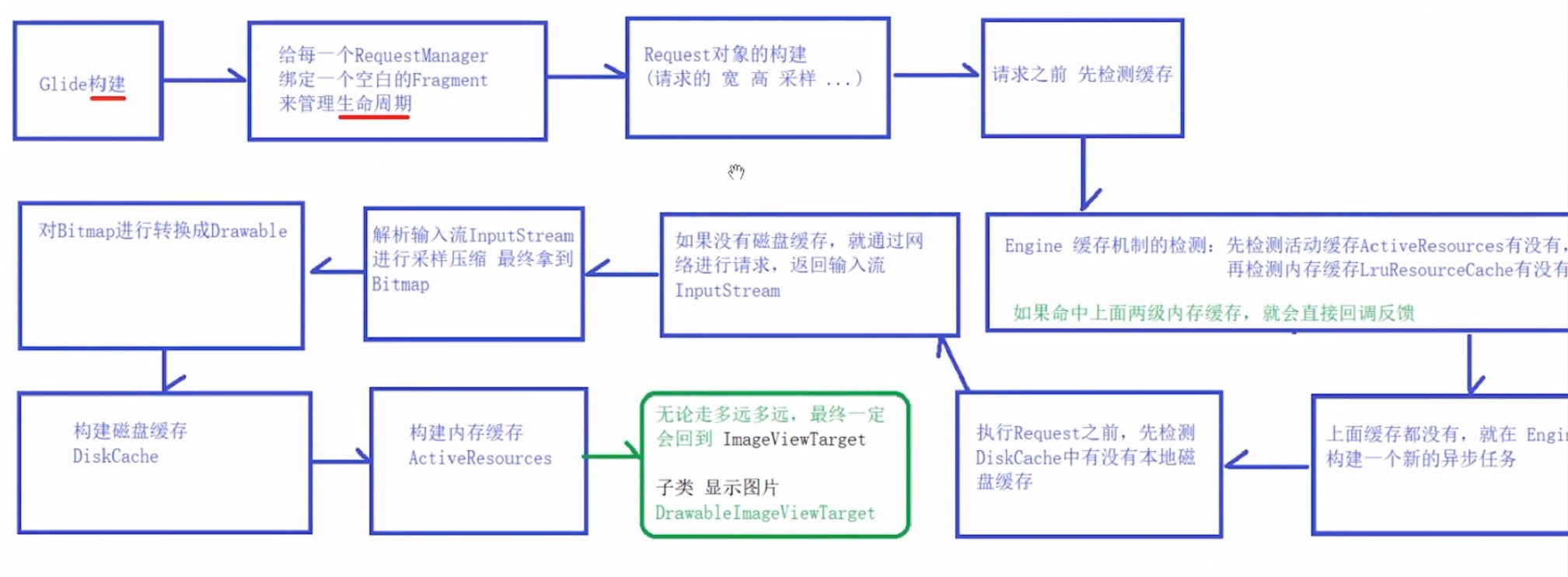
Glide
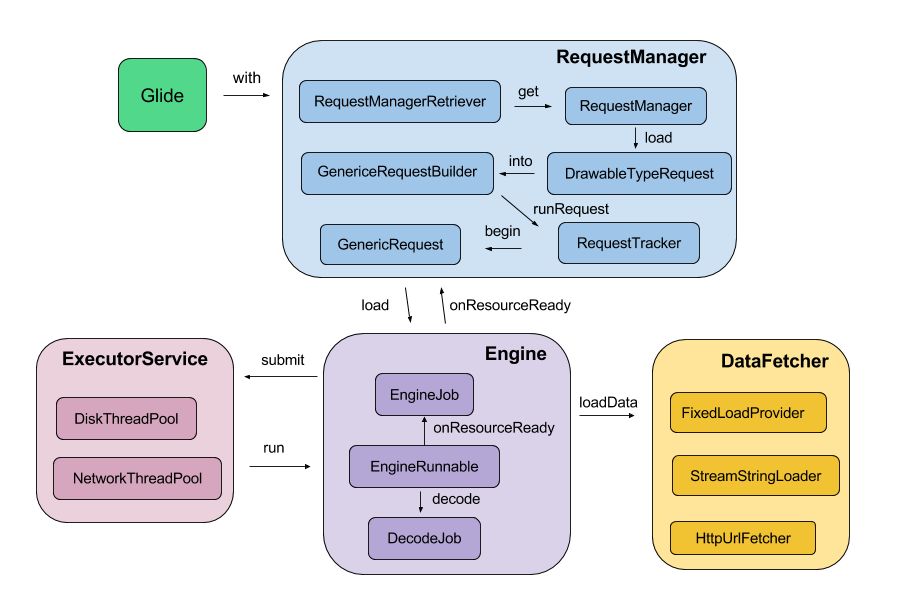
Glide: 初始化系统,负责管理系统其他模块如数据加载器、网络栈等初始化管理;RequestManager: 创建、初始化以及管理系统所有的 Request;Engine: 将资源加载请求放入执行线程池,加载完后返回给主线程;ExecutorService: 线程池执行服务,负责分发调度EngineRunnable可执行对象;DataFetcher: 从磁盘或者网络端加载数据
生命周期绑定
Glide 提供了两种生命周期管理策略:ApplicationLifecycle和ActivityFragmentLifecycle,前者确保 Request 的生命周期与 APP 的Application的生命周期保持一致;而后者则使 Request 的生命周期与Activity或者Fragment保持一致。
基于当前Activity添加无UI的Fragment,通过Fragment接收Activity传递的生命周期。Fragment和RequestManager基于Lifecycle建立联系,并传递生命周期事件,实现生命周期感知。在RequestManager初始化时,调用了lifecycle.addListener(this),将自己的引用存入lifecycle,从而实现与fragment关联。
生命周期传递
RequestManager实现了LifecycleListener接口。且在绑定阶段,在RequestManager的构造方法中,将RequestManager加入到了lifeCycle中。故回调LifecycleListener中的相关方法,可以调用到它里面的对request生命周期进行管理的方法。由此,实现了Request对生命周期的感知。
SupportRequestManagerFragment --> ActivityFragmentLifecycle --> RequestMananger
FragmentActivity.getSupportFragmentManager()
Activity.getFragmentManager()
Fragment: getChildFragmentManager()Glide的三级缓存机制
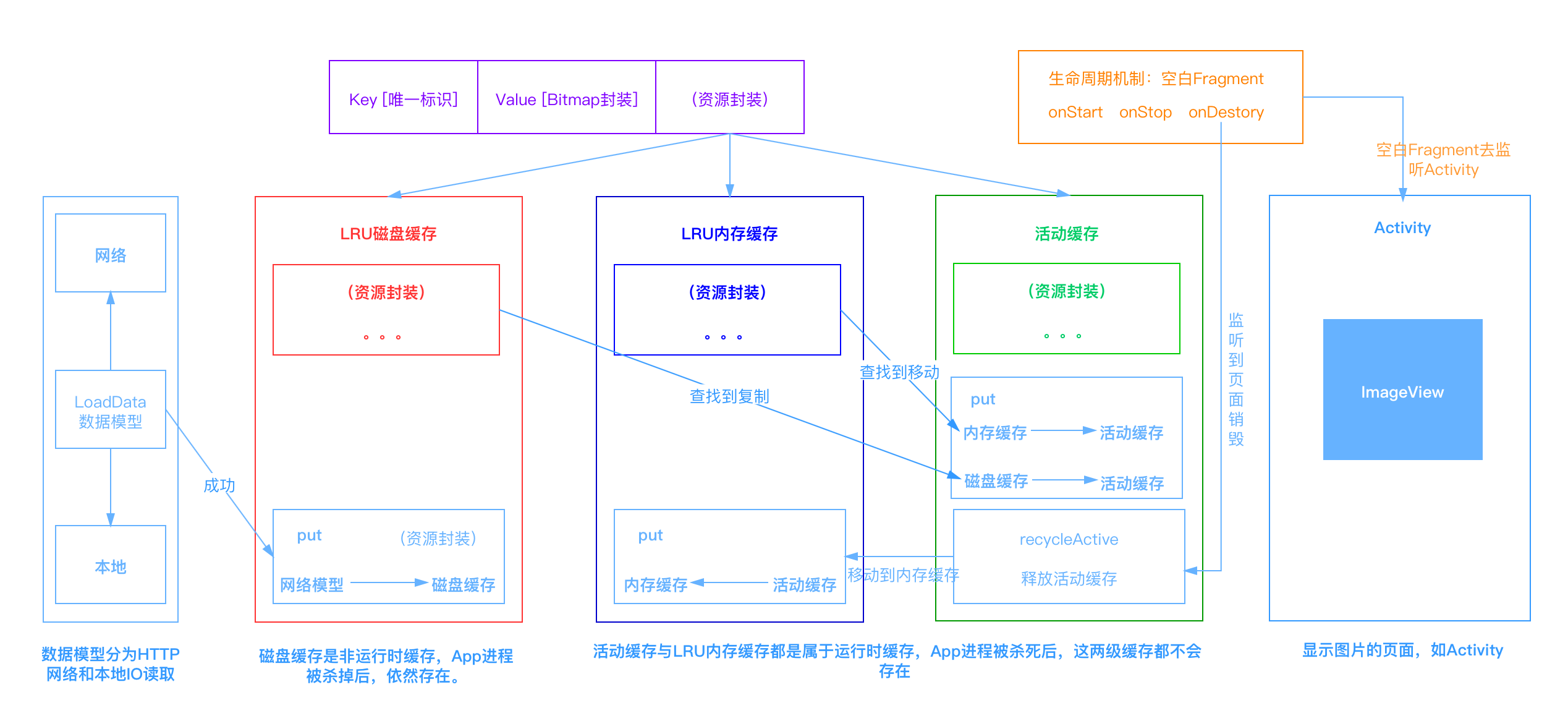
活动缓存:正在使用的图片,使用弱引用缓存图片,避免内存泄漏。图片回收后,保存到内存缓存中。(活动缓存存在的意义:防止内存缓存因LRU策略,正在使用的图片被回收的问题)
内存缓存:如果活动缓存找不到图片,就从内存缓存中查找,找到后”移动“到活动缓存。
磁盘缓存:上面两级缓存都没找到,就从磁盘缓存中查找,找到后”复制“到活动缓存。
LruCache中将LinkedHashMap的顺序设置为LRU顺序来实现LRU缓存,每次调用get(也就是从内存缓存中取图片),则将该对象移到链表的尾端。调用put插入新的对象也是存储在链表尾端,这样当内存缓存达到设定的最大值时,将链表头部的对象(近期最少用到的)移除。
Netty
BIO(Blocking I/O): 同步阻塞I/O模式,就是传统的 java.io 包,它是基于流模型实现的,交互的方式是同步、阻塞方式,也就是说在读入输入流或者输出流时,在读写动作完成之前,线程会一直阻塞在那里。 Java 1.4 之前的版本引入。
NIO(Non-blocking I/O): 同步非阻塞I/O模式,是 Java 1.4 引入的 java.nio 包,提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 I/O 程序,同时提供了更接近操作系统底层高性能的数据操作方式。
AIO(Asynchronous I/O): 异步非阻塞I/O模式,是 Java 1.7 之后引入的包,是 NIO 的升级版本,提供了异步非堵塞的I/O 操作方式,所以人们叫它 AIO,AIO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
Netty: Netty是一个基于异步事件驱动的NIO 框架,用于快速开发可维护的高性能的服务器和客户端。
I/O 复用模型
非阻塞 I/O 的实现关键是基于 I/O 复用模型, IO 线程 NioEventLoop 由于聚合了多路复用器 Selector,可以同时并发处理成百上千个客户端连接。
基于 Buffer
传统的 I/O 是面向字节流或字符流的,以流式的方式顺序地从一个 Stream 中读取一个或多个字节, 因此也就不能随意改变读取指针的位置。
在 NIO 中,抛弃了传统的 I/O 流,而是引入了 Channel 和 Buffer 的概念。在 NIO 中,只能从 Channel 中读取数据到 Buffer 中或将数据从 Buffer 中写入到 Channel。基于 Buffer 操作不像传统 IO 的顺序操作,NIO 中可以随意地读取任意位置的数据。
事件驱动模型
可扩展性好,分布式的异步架构,事件处理器之间高度解耦,可以方便扩展事件处理逻辑。
高性能,基于队列暂存事件,能方便并行异步处理事件。
DataBinding
原理
1.APT预编译方式生成ActivityMainBinding和ActivityMainBindingImpl
2.处理布局的时候生成了两个xml文件
activity_main-layout.xml(DataBinding需要的布局控件信息)
activity_main.xml(Android OS 渲染的布局文件)
Model是如何刷新View
1.DataBindingUtil.setContentView方法将xml中的各个View赋值给ViewDataBinding,完成findviewbyid的任务
2.当VM层调用notifyPropertyChanged方法时,最终在ViewDataBindingImpl的executeBindings方法中处理逻辑
View是如何刷新Model
ViewDataBindingImpl的executeBindings方法中在设置了双向绑定的控件上,为其添加对应的监听器,监听其变动,如:EditText上设置TextWatcher,具体的设置逻辑放置到了TextViewBindingAdapter.setTextWatcher里当数据发生变化的时候,TextWatcher在回调onTextChanged()的最后,会通过textAttrChanged.onChange()回调到传入的mboundView2androidTextAttrChanged的onChange()。
LiveData + ViewModel
onSaveInstanceState只适合保存少量的可以被序列化、反序列化的数据
onRetainNonConfigurationInstance 方法,用于处理配置发生改变时数据的保存。随后在重新创建的 Activity 中调用 getLastNonConfigurationInstance 获取上次保存的数据
LiveData是一个可被观察的数据容器类
它将数据包装起来,使得数据成为“被观察者”,页面成为“观察者”。这样,当该数据发生变化时,页面能够获得通
知,进而更新UI。
可以看到它接收的第一个参数是一个LifecycleOwner对象,在我们的示例中即Activity对象。第二个参数是一个
Observer对象。通过最后一行代码将Observer与Activity的生命周期关联在一起。
只有在页面处于激活状态(Lifecycle.State.ON_STARTED或Lifecycle.State.ON_RESUME)时,页面才会收到来自
LiveData的通知,如果页面被销毁(Lifecycle.State.ON_DESTROY)
不会发生内存泄漏
观察者会绑定到 Lifecycle 对象,并在其关联的生命周期遭到销毁后进行自我清理。
不再需要手动处理生命周期
如果观察者的生命周期处于非活跃状态(如返回栈中的 Activity ),则它不会接收任何 LiveData 事件。
getLifecycle().addObserver进行观察
activity实现LifecycleOwner,reprotfrgament注册
livedata继承LifecycleObserver,detsroy销毁 其他
liferecycle
LifecycleObserver:是一个空方法接口,用于标识观察者,对这个 Lifecycle 对象进行监听
LifecycleOwner: 是一个接口,持有方法Lifecycle getLifecycle()。
LifecycleRegistry 类用于注册和反注册需要观察当前组件生命周期的 LifecycleObserver
1.实现LifecycleOwner重写getLifecycle 返回mLifecycleRegistry,mLifecycleRegistry不同生命周期markState
2.继承LifecycleObserver
3.getLifecycle.addObserver注册LifecycleObserver
Boom
组件化
组件分为 基础组件、业务基础组件、业务组件。
优点:加快编译速度,提高协作效率
比较著名的路由框架 有阿里的ARouter、美团的WMRouter,它们原理基本是一致的。
APT是Annotation Processing Tool的简称,即注解处理工具。
ARouter: 1.@Route 2.ARouter.getInstance().build(“/xx/xx”).navigation()
@Route(path = "/cart/cartActivity")
public class CartActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_cart);
}
}@Route(path = "/homepage/homeActivity")
public class HomeActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_home);
findViewById(R.id.btn_go_cart).setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
//通过路由跳转到 购物车组件的购物车页面(但没有依赖购物车组件)
ARouter.getInstance()
.build("/cart/cartActivity")
.withString("key1","value1")//携带参数1
.withString("key2","value2")//携带参数2
.navigation();
}
});
}
}ARouter 路由表生成原理
@Route注解,会在编译时期通过apt生成一些存储path和activityClass映射关系的类文件
ARouter 路由表加载原理
app进程启动的时候会拿到这些类文件,把保存这些映射关系的数据读到内存里(保存在map里)到这些类文件便可以得到所有的routerAddress—activityClass映射关系 去扫描apk中所有的dex,遍历找到所有包名为packageName的类名,然后将类名再保存到classNames集合里
Arouter采用的方法就是“分组+按需加载”,分组还带来的另一个好处是便于管理
ARouter 跳转原理
路由跳转的时候,通过build()方法传入要到达页面的路由地址,ARouter会通过它自己存储的路由表找到路由地址对应的Activity.class(activity.class = map.get(path)),然后new Intent()
ARouter 组件与组件之间通信
intent:调用ARouter的withString()方法它的内部会调用intent.putExtra(String name, String value),调用navigation()方法,它的内部会调用startActivity(intent)进行跳转,这样便可以实现两个相互没有依赖的module顺利的启动对方的Activity了。
服务暴露组件,必须继承IProvider,是为了使用ARouter的实现注入。
除了组件间方法调用,使用EventBus在组件间传递信息也是ok的(注意Event实体类要定义在export_xxx中)。
第一步:注册子模块信息到路由表里面去,采用编译器APT技术,在编译的时候,扫描自定义注解,通过注解获取子模块信息,并注册到路由表里面去。
第二步:寻址操作,寻找到在编译器注册进来的子模块信息,完成交互即可。
组件的生命周期
AppLifecycle插件是使用了 APT技术、gradle插件技术+ASM动态生成字节码,在编译阶段就已经完成了大部分工作,无性能问题、且使用方便。
插件化
插件化的优势
1.减少主apk的体积、65535 问题。让应用更轻便
2.让用户不用重新安装 APK 就能升级应用功能,减少发版本频率,增加用户体验。
3.模块化、解耦合
类加载原理
BootClassLoader PathClassLoader DexClassLoader
双亲委派机制: ClassLoader在加载一个字节码时,首先会询问当前的 ClassLoader是否已经加载过此类,如果已经加载过就直接返回,不在重复的去加载,如果没有的话,会查询它的parent是否已经加载过此类,如果加载过那 么就直接返回parent加载过的字节码文件,如果整个继承线路上都没有加载过此类,最后由子ClassLoader执行真正的加载。
资源加载原理
Android系统通过Resource对象加载资源,Resource对象的生成只要将插件apk的路径加入到AssetManager中,
便能够实现对插件资源的访问。和代码加载相似,插件和主工程的资源关系也有两种处理方式:
合并式:addAssetPath时加入所有插件和主工程的路径;会引入资源冲突。
独立式:各个插件只添加自己apk路径;资源共享比较麻烦。
Activity加载原理
代理:dynamic-load-apk采用。 Hook:主流。
目前主流的插件化方案有滴滴任玉刚的VirtualApk、 Wequick的Small框架。
Hook实现方式有两种:Hook IActivityManager 和 Hook Instrumentation。
主要方案就是先用一个在AndroidManifest.xml中注册的SubActivity来进行占坑,用来通过AMS的校验,接着在合适的时机用插件Activity替换占坑的Activity。
startActivity-Instrumentation.execStartActivity()->ActivityManager.getService().startActivity()->
IActivityManager.Stub.asInterface->AMS.startActivity()
Hook IActivityManager
ActivityManager中getService()借助Singleton类实现单例,而且该单例是静态的,IActivityManager是一个比较好的
Hook点。由于Hook点IActivityManager是一个接口(源码中IActivityManager.aidl文件),建议这里采用动态代理。
1)占坑、通过校验
1.1 AndroidManifest.xml中注册SubActivity
1.2 拦截startActivity方法,获取参数args中保存的Intent对象,它是原本要启动插件TargetActivity的Intent。
1.3 新建一个subIntent用来启动StubActivity,并将前面得到的TargetActivity的Intent保存到subIntent中,便于以后还原TargetActivity。
2)还原插件Activity
hook点: Handelr中的mCallback
activity启动过程中, AMS会远程掉用applicationThread的scheduleLaunchActivity。
ActivityThread中的Handler -> h的handleLaunchActivity处理LAUNCH_ACTIVITY类型的消息 ->
ActivityThread#handleLaunchActivity -> instmentiong启动activity -> Activity的onCreate方法。
在Handler的dispatchMessage处理消息的这个方法中,看到如果Handelr的Callback类型的mCallBack不为null,就会执行mCallback的handleMessage方法,因此mCallback可以作为Hook点。我们可以用自定义的Callback来替换mCallback。重写callback,当收到消息的类型为LAUNCH_ACTIVITY时,将启动SubActivity的Intent替换为启动TargetActivity的Intent。反射获取ActivityThread,反射获取mH,替换callback使用时则在application的attachBaseContext方法中进行hook即可。
Hook Instrumentation方案
1.在Instrumentation的execStartActivity方法中用占坑SubActivity来通过AMS的验证
首先检查TargetActivity是否已经注册,如果没有则将TargetActivity的ClassName保存起来用于后面还原。接着把要启动的TargetActivity替换为StubActivity,最后通过反射调用execStartActivity方法,这样就可以用StubActivity通过AMS的验证。
2.在Instrumentation的newActivity方法中还原TargetActivity
在newActivity方法中创建了此前保存的TargetActivity,完成了还原TargetActivity。
用InstrumentationProxy替换mInstrumentation。
3.插件Activity的生命周期
AMS和ActivityThread之间的通信采用了token来对Activity进行标识,并且此后的Activity的生命周期处理也是根据token来对Activity进行标识的,因为我们在Activity启动时用插件TargetActivity替换占坑SubActivity,这一过程在performLaunchActivity之前,因此performLaunchActivity的r.token就是TargetActivity。所以TargetActivity具有生命周期。
热修复
类加载 动态代理 反射
1. 阿里AndFix
AndFix采用native hook的方式,这套方案直接使用dalvik_replaceMethod替换class中方法的实现。由于它并没有整体替换class, 而field在class中的相对地址在class加载时已确定,所以AndFix无法支持新增或者删除filed的情况(通过替换init与clinit只可以修改field的数值)。也正因如此,Andfix可以支持的补丁场景相对有限,仅仅可以使用它来修复特定问题。结合之前的发布流程,我们更希望补丁对开发者是不感知的,即他不需要清楚这个修改是对补丁版本还是正式发布版本(事实上我们也是使用git分支管理+cherry-pick方式)。另一方面,使用native替换将会面临比较复杂的兼容性问题。
2.美团Robust
Robust插件参考Android Studio 2.0的新特性Instant Run, 实现了对代码修改的实时生效(热插拔)。
Robust插件利用APT技术,对每个产品代码的每个函数都在编译打包阶段自动的插入了一段代码,插入过程对业务开发是完全透明。
3.微信Thinker
采用DexDiff算法减小补丁包大小,它的粒度是Dex格式的每一项,可以充分利用原本Dex的信息,而BsDiff的粒度是文件,AndFix/QZone的粒度为class。
采用Dex全量替换方式,将合成的dex文件通过反射插入到dexElements中,并放置在数组第一个索引位置,下次进行类加载的时候classLoader加载新生成的dex文件
为什么需要重启app生效
1、运行时通过反射将合并后的dex文件放置在加载的dexElements数组的前面
2、只有app重新启动的时候才会classLoader才会遍历Elements数组中dex文件,加载dex中的类文件
3、当一个apk在安装的时候,apk中的classes.dex会被虚拟机(dexopt)优化成odex文件,然后才会拿去执行。
只要把有问题的类修复后,放到一个单独的dex,通过反射插入到dexElements数组的最前面,实现让虚拟机加载打完补丁的class。
Thinker,QZone 需要重启, Robust, Anfix 不需要重启
Other
LeakCanary
ReferenceQueue
如果软/弱/虚引用中的对象被回收,那么软/弱/虚引用就会被 JVM加入关联的引用队列ReferenceQueue中
是说我们可以通过监控引用队列来判断Reference引用的对象是否被回收,从而执行相应的方法。
1.了Application类提供的registerActivityLifecycleCallback(ActivityLifecycleCallbacks callback)方法来注册ActivityLifecycleCallbacks回调,这样就能对当前应用程序中所有的Activity的生命周期事件进行集中处理,当监听到Activity 或 Fragment onDestroy() 时,把他们放到一个弱引用WeakReference 中。
2.把弱引用WeakReference 关联到一个引用队列ReferenceQueue。(如果弱引用关联的对象被回收,则会把这个弱引用加入到ReferenceQueue中)。
3.延时5秒检测ReferenceQueue中是否存在当前弱引用对象。
4.如果检测不到说明可能发生泄露,通过gcTrigger.runGc()手动掉用GC。 遍历ReferenceQueue中所有的记录,当未回收对象个数大于5个时,dump heap获取内存快照hprof文件。
6.使用Shark解析hprof文件,Hprof.open()把heapDumpFile转换成Hprof对象,
7.根据heap中的对象关系图HprofHeapGraph获取泄露对象的objectIds
8.找出内存泄漏对象到GC roots的最短路径
9.输出分析结果展示到页面。
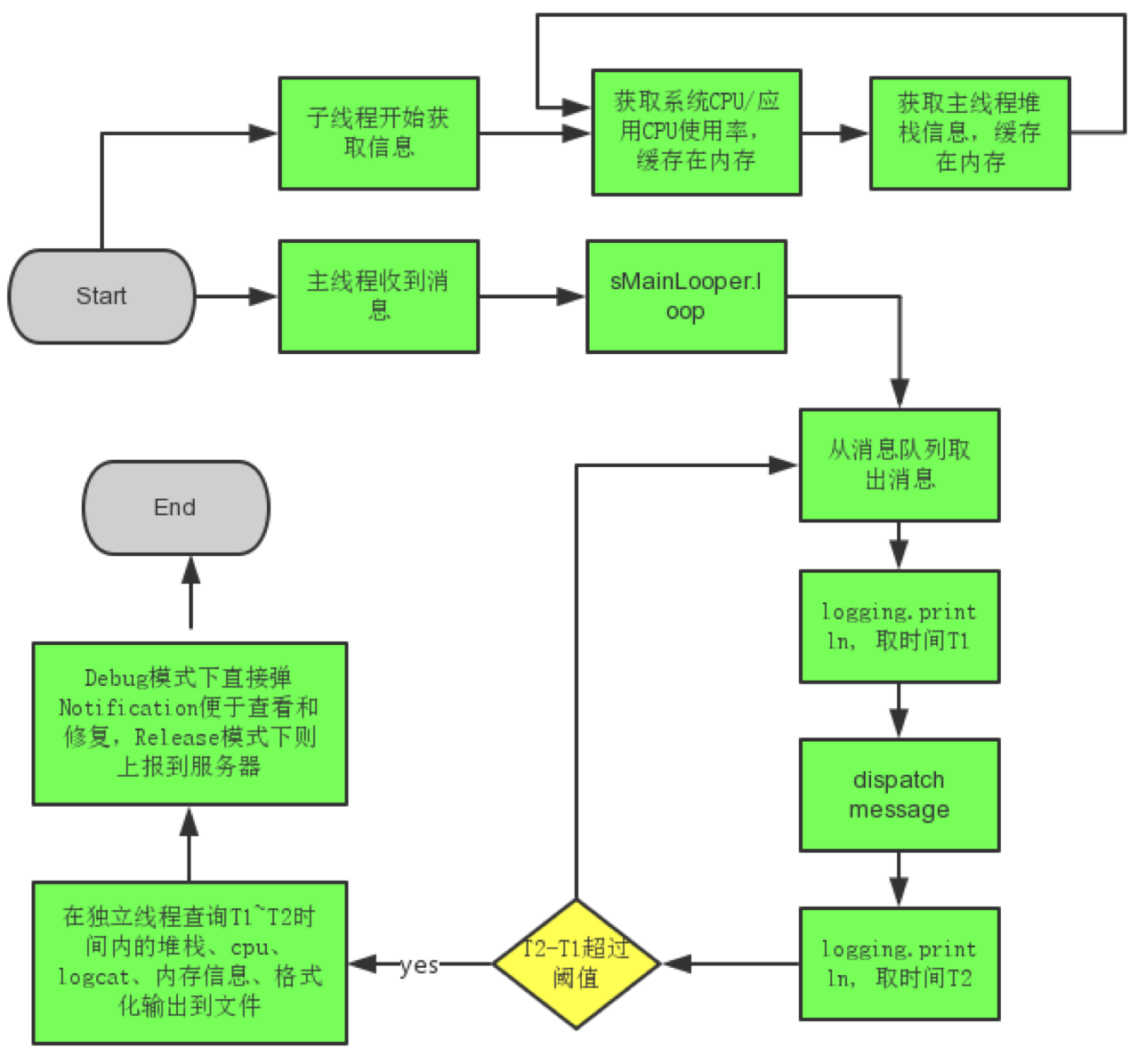
BlockCanary
BlockCanary对主线程操作进行了完全透明的监控,并能输出有效的信息,帮助开发分析、定位到问题所在,迅速优化应用。其特点有:
- 非侵入式,简单的两行就打开监控,不需要到处打点,破坏代码优雅性。
- 精准,输出的信息可以帮助定位到问题所在(精确到行),不需要像Logcat一样,慢慢去找。
目前包括了核心监控输出文件,以及UI显示卡顿信息功能。仅支持Android端。
Looper.getMainLooper().setMessageLogging(mainLooperPrinter);